如何整治各种网络爬虫(比如SemrushBot)
最近一段时间网站的访问量一直有异常,具体的表现就是访问量一直很大,但是uv跟pv却很低,这种情况大概率就是爬虫惹的祸,爬虫会不停的爬取接口数据,而不需要通过访问页面,由于一般的统计插件都是需要在页面加载完成后才进行统计的,所以就导致数据访问量很大,页面访问量很少。
看了下最近访问的日志,发现大量的爬虫,包括但不限于以下这些:bingbot
, SemrushBot, Googlebot, Applebot, LieBaoFast, Sogou web spider, Amazonbot。
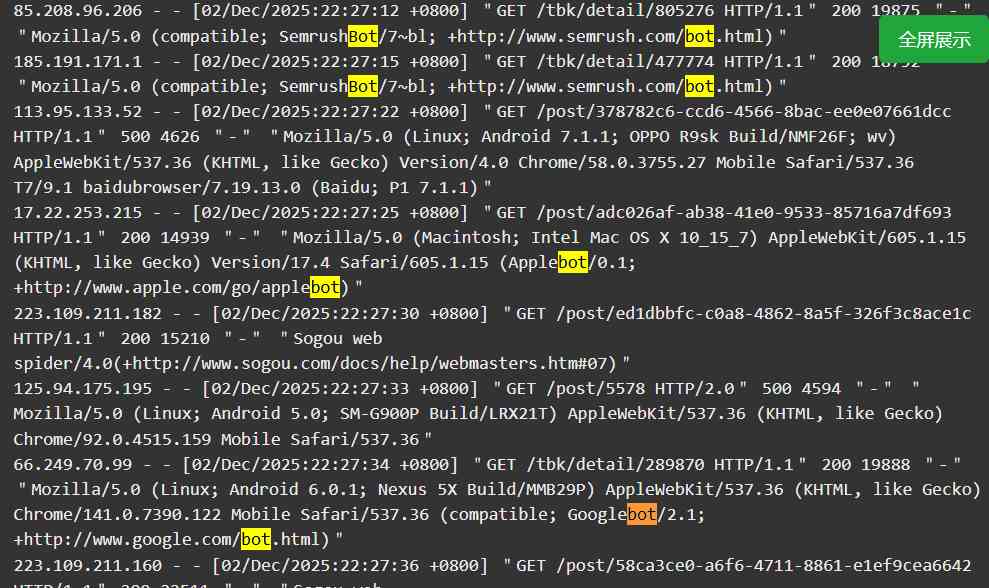
从这些爬虫来看好像都是正常的爬虫,比如bing跟google等,这个爬虫对网站的内容进行爬取,后续可能会将网站内容索引到它的搜索引擎中,对于网站来说是一件好事。
但是像SemrushBot这种商业爬虫,会不停的爬取,导致网站访问量居高不下,从而有可能导致正常的用户都无法访问。
可以通过网站的robots.txt文件来对不同的爬虫设置不同的策略,突然发现之前网站居然没设置内容,趁着这次机会顺便加上一些规则,当然主要还是针对SemrushBot爬虫,禁止它爬取任何内容,其次告诉所有爬虫不要爬取_nuxt目录,因为这个目录是网站的静态资源,爬取这些内容毫无意义,只会给服务器带来大的压力。
User-Agent: *
Disallow: /_nuxt/
User-Agent: SemrushBot
Disallow: /最近因为爬虫的原因,网站无端端的出现过好几次停止服务的情况,每次都是等到晚上下班回家后才发现,一整天网站都无法打开,这种无论是对正常的用户还是搜索引擎来说都造成了困扰,后续可能就压根就不会再来了。
每次服务停止的时候都需要登录到云服务后台手动对某个停止的服务进行重启,比较麻烦,当然实在不行就对服务器进行一键重启,万事大吉。
目前继续观察,看看添加的规则是否有效,如果不行只能在找找其他方案了。

发表评论 (审核通过后显示评论):